author: Sat Naing pubDatetime: 2022-09-23T15:22:00Z title: Adding new posts in AstroPaper theme postSlug: adding-new-posts-in-astropaper-theme featured: true draft: false tags:
- docs ogImage: "" description: Some rules & recommendations for creating or adding new posts using AstroPaper theme.
Background
Google’s Dataflow is a runner for Apache Beam. Apache beam is a unified and portable batch and streaming data processing framework. Dataflow is one of the popular beam runner. FlinkRunner and SparkRunner are also popular choices in community. Here’s a capability matrix for reading pleasure.
Why Dataflow
-
Not available from other cloud vendors
-
Born from Google technologies. Active involvement from Google engineers
-
Dataflow specific features
- Shuffle Service, Streaming Engine
- FlexRS
- GPU Support
- IAM, Monitoring, Logging built-in
-
Optimizations
- Graph optimization
- Fusion, combine
- Auto scaling and sharding
- Graph optimization
-
New features
- Prime - VPA (similar to k8 VPA), better monitoring and scaling
Overall Architecture
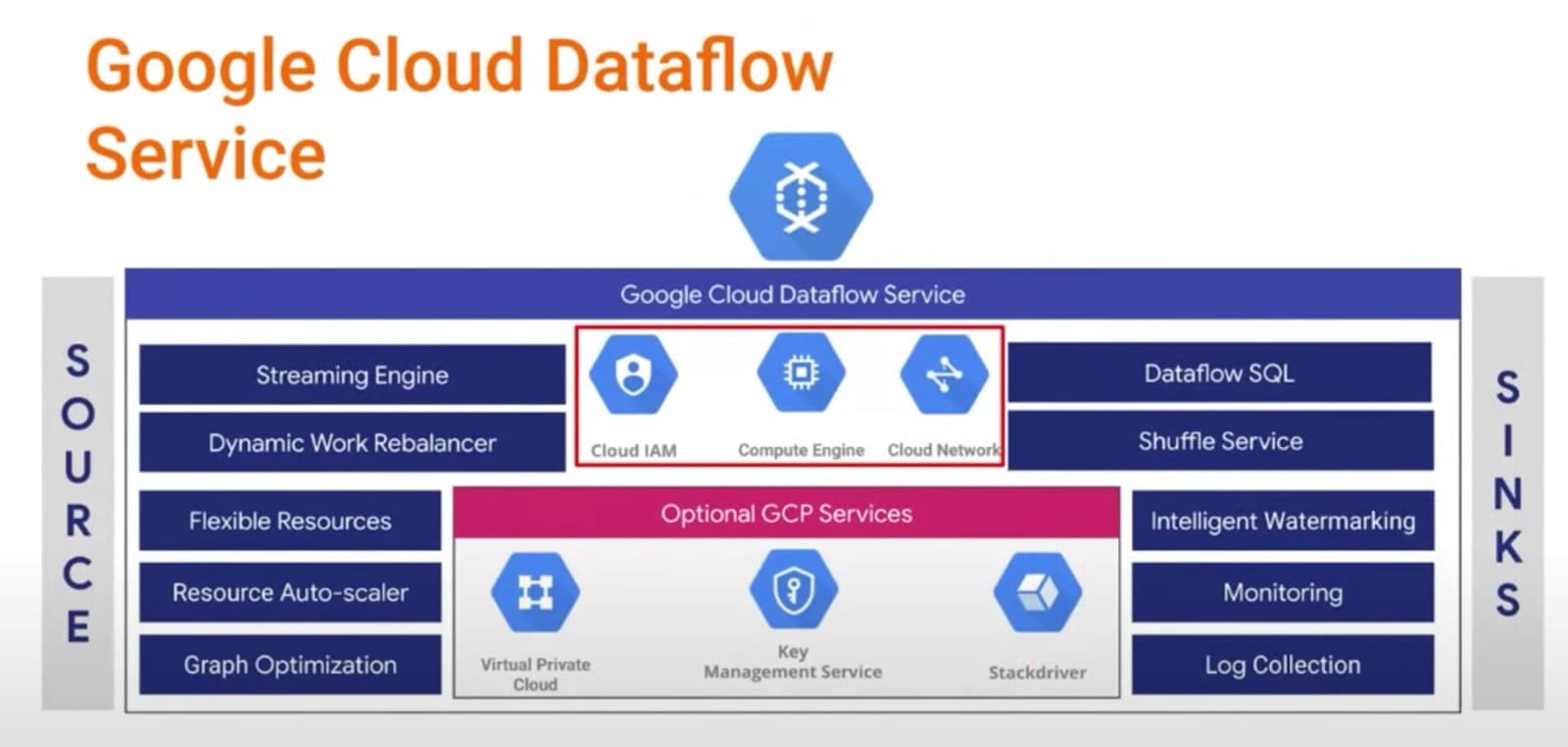
V2 portable runner
https://www.youtube.com/watch?v=tXdnPKPnY3E&list=PLjYq1UNvv2UcrfapfgKrnLXtYpkvHmpIh&t=396s
From code to dataflow job
https://www.youtube.com/watch?v=udKgN1_eThs&t=250s
Read
Summary
To summarize, below are the diffrent stages of manifest
- Code
- Graph (graph construction time)
- Traverse from main entry point to generate nodes of graph
- Executes locally on the machine that runs the pipeline (2b differs depending on use of classic vs flex template)
- Validates all resources (GCS, PubSub, etc)
- Check other errors
- Job (job creation time)
- Translated to JSON format and sent it to Dataflow service endpoint
- Validates JSON and replies with jobId
- Becomes a job on the Dataflow Service
- Job Execution Time
- The Dataflow service starts provisioning worker VMs. Serialized processing functions from the execution graph and required libraries are downloaded to the worker VMs and the Dataflow service starts distributing the data bundles to be processed on these VMs.
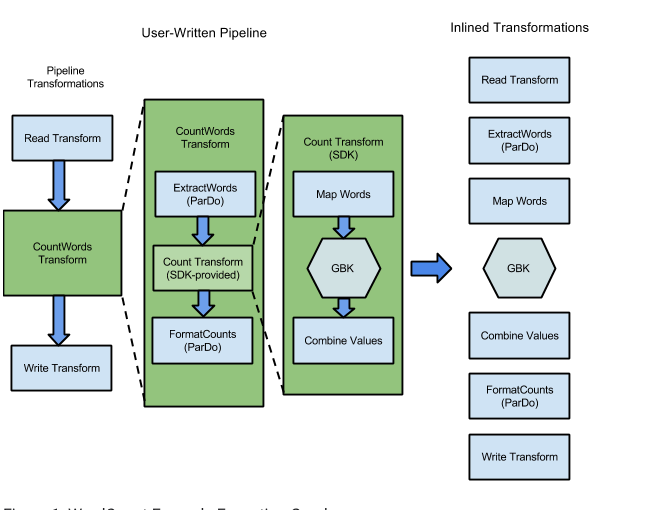
Sample execution graph (WordCount)
Unique services to dataflow
Shuffle Service
https://youtu.be/udKgN1_eThs?t=519
Streaming Engine
https://youtu.be/tXdnPKPnY3E?list=PLjYq1UNvv2UcrfapfgKrnLXtYpkvHmpIh&t=396
FlexRS
https://youtu.be/udKgN1_eThs?t=659
Dataflow graph optimizations
https://youtu.be/udKgN1_eThs?t=74
Auto scaling and sharding
These are two different concepts. Personally I consider
Auto-sharding = dynamically adjust partition size Auto-scaling = dynamically adjust worker size
Auto sharding and scaling
https://youtu.be/tXdnPKPnY3E?list=PLjYq1UNvv2UcrfapfgKrnLXtYpkvHmpIh&t=985
Auto-sharding
https://www.youtube.com/watch?v=udKgN1_eThs&t=461s
New features
Dataflow Prime
https://youtu.be/udKgN1_eThs?t=813
Resources
- https://cloud.google.com/dataflow/docs/guides/deploying-a-pipeline#pipeline-lifecycle:-from-pipeline-code-to-dataflow-job
- https://cloud.google.com/blog/products/data-analytics/introducing-cloud-dataflows-new-streaming-engine
- https://cloud.google.com/blog/topics/developers-practitioners/why-you-should-be-using-flex-templates-your-dataflow-deployments
- Best Practices